
نعمل في موقع معالج على تفصيل كل شيء فيما يتعلق بشرائح المعالجة SoC. وأنواع الأنوية وتصميمها هو جزء لا يتجزأ من هذا التفصيل.
ورغم حرصنا على تصغير حجم هذا المقال على أكبر قدر، لكن مع تعقيد الموضوع، وسعينا للإلمام بالكثير من النواحي فيما يتعلق بتصاميم الأنوية وتوضيح أهمية أنوية Cortex X1 و Cortex A78 وصلنا في النهاية إلى مقال كبير يحتاج الكثير من التركيز، لهذا إذا لم تكن مهتما بجميع أجزائه، ولا تريد التعمق في الجانب التقني للموضوع -رغم أني لا أعتقد أنك كذلك-، فيمكنك التنقل للجزء الذي تريده مباشرة من واجهة التنقل السريع هذه، أما إذا كنت تود قرائة مفصلة، فأحضر قهوتك وابدأ.
- نظرة للخلف، لماذا نحتاج أنوية Cortex X1 وبشدة!
- الأنوية داخل المعالج المركزي (المعالج المركزي سابقا)
- أنوية ARM Cortex A78 الأولوية لتوفير الطاقة..
- أولاً: مرحلتي الـ fetch و الـ decode:
- ثانيًا: مرحلتي الـ Execute والـ Write Back:
- أنوية ARM Cortex X1 الأداء قبل كل شيء..
- أولاً: مرحلتي الـ fetch و الـ decode:
- ثانيا: مرحلتي الـ Executeو الـ Write Back:
نظرة للخلف، لماذا نحتاج أنوية Cortex X1 وبشدة!
في عالم الهواتف الذكية تكتسح شركة ARM تصميم أنوية المعالجات المركزية، خاصة مع عدم وجود منافس حقيقي قادر على تصميم أنوية قوية غير شركة ابل -والتي تستخدم معمارية ARM في النهاية-.
ويعزي تفوق شركة ابل على ARM في أن الأولى تقوم بتصميم الأنوية لإستخدامها في شرائحها فقط، التي هي شرائح رائدة بالضرورة؛ بينما على النقيد تصمم ARM الأنوية ليتم استخدامها فيما بعد من الشركات المصممة للمعالجات مثل كوالكوم، وميدياتك، وهايسيليكون، وسامسونج. وكل من هذه الشركات تستخدم تصاميم الأنوية في معالجات رائدة أو متوسطة.
وهنا تكمن المشكلة التي تواجه ARM، حيث أن الشركة قادرة على تصميم أنوية قوية للغاية تتفوق حتى على أنوية شركة ابل، لكن في هذه الحالة لا يمكن إلا أن يتم تصنيعها على أحدث تقنية تصنيع متاحة، وقد يكون هذا هو الوضع بالفعل في المعالجات الرائدة، لكن المشكلة تكمن مع المعالجات المتوسطة، حيث غالبا يتم بنائها على تقنية تصنيع أقدم من أجل خفض تكلفة الإنتاج، وهنا لو قامت ARM بتصميم نوى قوية للغاية سيكون أمام شركات تصميم شرائح المعالجة عدة خيارات:
- الأول: أن لا تستخدم أنوية كبيرة مطلقا في تصميم المعالجات المتوسطة مما سيقلل الأداء للغاية.
- والثاني: أن تستخدم أنوية كبيرة وتضطر لاستخدام أحدث تقنية تصنيع مما سيرفع تكلفة المعالج بشكل كبير.
- والثالث: أن تستخدم الشركة تقنية تصنيع قديمة وتستخدم أنوية كبيرة مع خفض التردد بنسبة كبيرة حتى يستطيع المعالج الحفاظ على درجة حرارته و والتقليل من استهلاك الطاقة.
ولكن جميع الخيارات غير ممكنة؛ حيث أن الأول سيجعل أداء المعالجات المتوسطة يقل إلى درجة المعالجات المنخفضة، والثاني سيرفع تكلفة المعالج بشكل كبير مما يجعل استخدام الرقاقات الرائدة خيارا أفضل، والثالث وعلى الرغم من التغلب على درجات الحرارة المرتفعة واستهلاك الطاقة بخفض التردد، إلا أنه كان يمكن الحصول على نفس النتائج بأنوية أصغر بكثير وأقل كثيرا في تكلفة الإنتاج.
في هذه الظروف لم يكن أمام ARM إلا أن يكون أولوياتها في تصميم الأنوية الكبيرة هو الإهتمام أولا بجعل حجمها صغير قدر المستطاع ليناسب المعالجات المتوسطة، بالإضافة للتركيز على استهلاك الطاقة لتعطى أداء ثابتا حتى مع تصنيعها على تقنيات قديمة نسبيا.
ومع استمرار ARM في هذه الفلسفة التصميمية لعدة أجيال، وبالتوازي مع استمرار ابل في زيادة أداء الأنوية الكبيرة بنسب مرتفعة كل عام، أصبح الفارق بين قوة أداء النواة الواحدة مهولا بين هواتف الأندرويد وأجهزة ابل، لدرجة أن نواتين كبيرتين فقط من تصميم أبل تعطي نتائج أفضل من أربع أنوية مجتمعة من تصاميم ARM، فأصبح محتما على ARM أن تقدم نموذجا جديدا في فلسفتها التصميمية، حتى لا تخسر السوق مقابل اتجاه كل شركة إلى تصميم أنويتها المعدلة.
وللأسباب التي أوضحناها بالأعلى فإنه لا يمكن بحال أن تغير ARM الأسس التي بُنيت عليه سلسلة Cortex A، وإلا اضطرت شركات تصميم شرائح المعالجة للبحث عن بدائل أخرى لدعم معالجاتها المتوسطة، فكان الحل هو الحفاظ على سلسلة A كما هي، مع إضافة سلسلة جديدة تماما تحمل المواصفات الرائدة المطلوبة وهي سلسلة Cortex X.
في الأسطر القادمة سنقوم باستعراض كلا من أنوية ARM Cortex A78 وأنوية ARM Crotex X1 الجديدة، ملقين النظر على ما تقدمانه من زيادة في الأداء أو تحسينات في توفير الطاقة. لكن طالما أن هذه أول تغطية لنا من هذا النوع، بالإضافة إلى حقيقة أن أغلب المستخدمين لا يعرفون الأسس التصميمية التي يُبنى عليها الأنوية؛ فسنقوم سريعا بشرح تلك الأسس والوقوف على أهم الأجزاء التي تتكون منها الأنوية حتى يتسنى للقارئ فهم ما سنستعرضه في باقي أجزاء المقال.
الأنوية داخل المعالج المركزي (المعالج المركزي سابقا)
قبل التطرق لتصاميم أنوية ARM Cortex A78 وأنوية ARM Crotex X1 سنبدأ أولا هذا الشرح المختصر بتوضيح مفهوم بسيط سيزيل عنك الكثير من اللبس. وهو أن الأنوية التي يتكون من مجموعها المعالج المركزي CPU، كانت سابقا هي الـ CPU في حد ذاته، فالنواة الواحدة تحمل كل الأجزاء المطلوبة للقيام بعمليات المعالجة كاملة، وكان هذا هو الحال لفترات طويلة مضت، ثم ظهر مفهوم الحوسبة المتزامنة وظهرت تبعا له شرائح المعالجة متعددة الأنوية، حيث توزع العمليات على الأنوية (المعالجات المركزية) لتسريع وقت خروجها من المعالج. لهذا ما سنوضحه الآن على أنه تصميم أنوية المعالج، كان يتم شرحه في فترات سابقة على أنه تصميم المعالج المركزي ذاته؛ وحتى يتم إتمام معالجة أي حزمة من البيانات، فإنها يجب أن تمر بأربع مراحل، وهي الإحضار (fetch) والفك (decode) والإنهاء (execute) والكتابة (write-back):
- مرحلة الإحضار (fetch): وفيها يتم جلب العملية التي تحتاج للمعالجة إلى داخل النواة.
- مرحلة الفك (decode): وهنا يتم معرفة نوع العملية لتوجيهها للجزء الصحيح في النواة لتتم معالجتها.
- مرحلة الإنهاء (execute): حيث يتم معالجة هذه العملية.
- أما مرحلة الكتابة (write-back): فهي كتابة ناتج المعالجة على الذاكرة العشوائية.
وكل من هذه العمليات تتضمن الكثير من الخطوات، فكما أن المعالج المركزي يحتوي على عدة أنوية تعمل بشكل متوازي، فإن كل مرحلة من هذه المراحل قد تحتوى على أكثر من وحدة للقيام بعدة عمليات داخل النواة الواحدة في نفس الوقت.
بعد هذا الشرح السريع -المخل على الأرجح- يمكننا الآن أن نتطرق لشرح تصاميم أنوية ARM Cortex A78 وأنوية ARM Crotex X1 الجديدة، وإذا لم تكن مهتما بفهم آلية عمل شريحة المعالجة من الداخل، وكيف تؤدي تغيرات بسيطة في التصميم إلى نتائج مختلفة للغاية في النهاية، فيمكنك الإنتقال مباشرة إلى الجزء الممل في نهاية المقال المتعلق بـ نتائج الأداء، أما إذا كنت تريد الجزء الممتع، فسنبدأ به على الفور.
أنوية ARM Cortex A78 الأولوية لتوفير الطاقة..
أولاً: مرحلتي الـ fetch و الـ decode:
يبدأ الجزء الأول من النواة بقسم يسمى الـ branch prediction، وهو المسؤول عن عملية الجلب أو الـ fetch، ومهمته هي التنبؤ بالعمليات التي سيحتاجها البرنامج تاليا ليقوم بجلبها مقدما وإدخالها للنواة، وهذا لتسريع عملية الجلب بدلا من انتظار البرنامج لطلب العملية التالية في كل مرة، لكن بالطبع لا يخلو هذا التنبؤ من أخطاء، مما يضطر النواة إلى تفريغ محتوى العمليات التي بداخلها من لحظة حدوث هذا الخطأ، والبدء من عند أخر نقطة تمت معالجتها.
وهنا يظهر أول وأكبر التحسينات التي تمت على أنوية Cortex A78، حيث أن وحدة الـ branch prediction أصبحت الآن قادرة على تقديم تخمينين في الدورة الواحدة بدلا من تخمين واحد في الأنوية السابقة A77، مما يزيد سرعة دخول العمليات لمرحلة الـ decode، ومن جهة أخرى تقلل من الوقت اللازم لجلب العملية الصحيحة التالية في حالة حدوث خطأ.
هذا مع وجود تحسينات في أداء الـ preceptor للحصول على دقة توقع أفضل للعمليات القادمة – أعتقد أنها قد تتخطى حاجز الـ 85 بالمائة – في أنوية Cortex A78.
وما إن يأتي الـ Predictor بالتعليمة التالية حتى يتم تخزينها في ذاكرة الكاش من المستوى الأول L1 Cache، وفي أنوية Cortex A78 أتجهت ARM إلى وضع خيارين لشركات تصميم الشرائح، إما استخدام Cache بحجم 64 كيلوبايت كما في السابق، أو النزول إلى خيار 32 كيلوبايت فقط. قد يبدو هذا محبطا لكن كما سبق، فإن أنوية Cortex A78 تستهدف توفير الطاقة قبل أي شيء.
وبجانب الـ L1 Cache ستجد الـ Mop Cache لكن سنؤجل الحديث عنه إلى ما بعد عملية الـDecode والـ Rename.

حسنا، بعد أن تدخل التعليمة إلى ذاكرة الكاش يحن الدور على الـ Decoder ليسحب التعليمة أو Instruction التي أتى دورها في تسلسل التعليمات، ثم يقوم بتفكيكها إلى أجزاء صغيرة تسمى Micro-Ops، فالتعليمة ما هي إلا عدد من الـ Micro-Ops أو التعليمات المصغرة مثل الجمع أو الضرب، وبعد هذا يوجهها إلى قسم الـ Rename.
وهنا نعود إلى كاش الـ Micro-op الذي كان بجانب الكاش من المستوى الأول، فكما يتضح من الاسم فإنه لا يعمل على تخزين التعليمات (Ins) كاملة كما في كاش التعليمات، بل يقوم بتخزين التعليمات المصغرة (M-Ops) بعد تقسيمها من وحدة الـ Decode فإذا احتاجتها النواة ثانية تقوم بجلبها مباشرة دون الحاجة إلى مرورها بمرحلة التفكيك ثانية، وهنا تستطيع أنوية Cortex A78 تخزين 1500 عملية مصغرة في كاش العمليات المصغرة وهذا نفس عدد العمليات التي كانت تحملها أنوية Cortex A77 السابقة.
نعود إلى مرحلة إعادة التسمية أو Rename، والهدف من هذه المرحلة هو إعادة تسمية مكان التسجيل الخاص بالتعليمة وتحويله لـ Register فعلي.
للتوضيح: يتم ترتيب العمليات داخل البرنامج المكتوب بلغة الأسمبلي وفقا لقواعد محددة تسمى Instruction Set، وهنا بالطبع نحن نتحدث عن الـ Instruction Set الخاصة بـ ARM، ويكون البرنامج قد أعطى لكل تعليمة مكان Register وهمي أو نظري (x0-x31) مثلا حتى يستطيع ترتيب عمليات البرنامج بشكل صحيح، هذا الـ Register النظري لا يتطابق مع وحدات المسجلات داخل النواة التي يتم ملؤها وتفريغها مع كل عملية تمر بمرحلة الإنهاء.
وهنا يكون الهدف من عملية الـ Rename هو تحديد أي عملية ستوضع في أي Register وإعطائها مكان الـ Register استعدادا لدخول مرحلة الـ Execution.
وتبعا لـ ARM فإن ملفات الـ Register في أنوية Cortex A78 قد تم تخصيصها من أجل توفير أفضل للطاقة، وتمت إعادة تصميمها بشكل يجعلها قادرة على حمل بيانات أكثر داخل نفس المساحة.
بعد مرحلتي الفك وإعادة التسمية، تأتي مرحلة الـ Dispatch أو الإرسال، حيث يتم أخيرا نقل العمليات المصغرة إلى قسم الإنهاء أو الـ Execute حيث يتم تنفيذ العمليات والتعديل على البيانات.
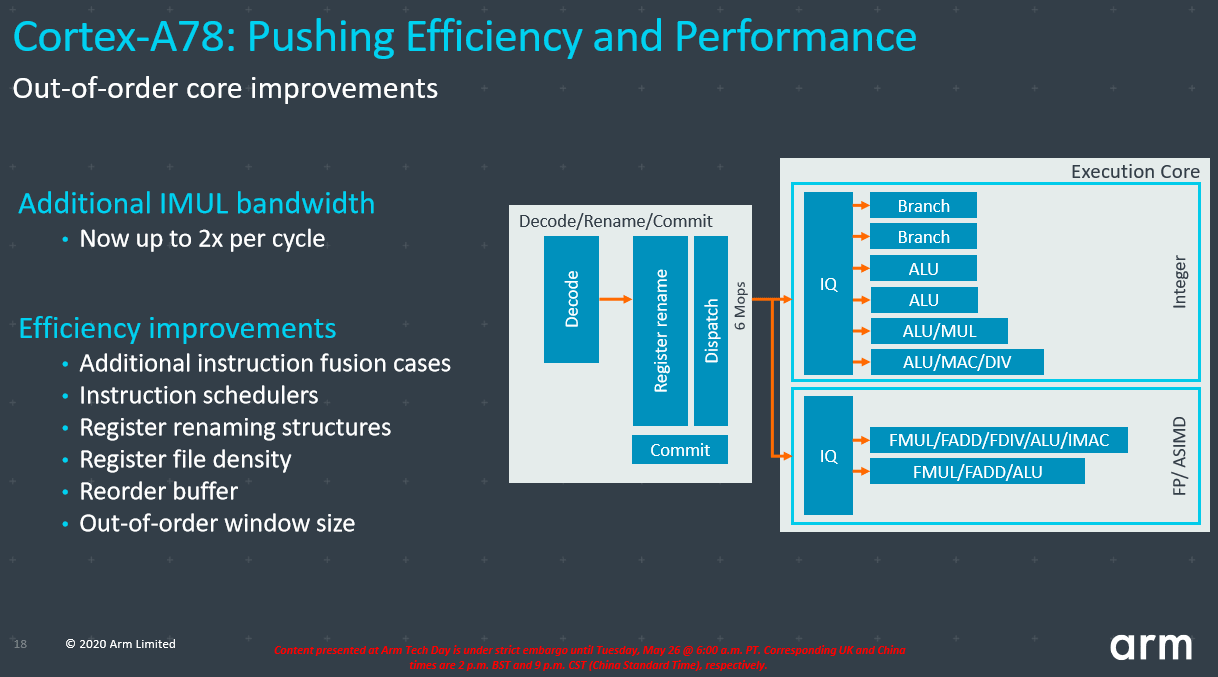
ثانيًا: مرحلتي الـ Execute والـ Write Back:
بعد أن وصلت التعليمات إلى مرحلة الـ Dispatch، تبدأ الـ Issue Queue أو طوابير التدفق بطلب تلك العمليات؛ وتستطيع أنوية Cortex A78 إيصال ست عمليات مصغرة (Mops) بدلا من 5 عمليات في أنوية Cortex A75 مما يزيد من العمليات الداخلة لوحدات الـ ALU بنسبة جيدة.
لكن ليست جميع طوابير التدفق متماثلة، فكما سنرى لاحقا، فإن الجزء الأخير في النواة ينقسم لقسمين رئيسين، وهما الـ Floating Point والـ Integer، ووحدات الـ IQ أو طوابير التدفق مقسمة لنوعين من الطوابير لإيصال العمليات لجزئي النواة. وكل طابور لا يطالب إلا بالعمليات المتعلقة بالجزء الخاص به. كل من هذين الجزئين يسميان Execution Unit أو وحدة تنفيذ، ففي أنوية Cortex A78 -وأنوية Cortex X1 أيضا- لدينا وحدتان تنفيذ الأولى مخصصة لعمليات الـ Integer والثانية لعمليات الـ Floating.
وحدة التنفيذ الخاصة بعمليات الـ Integer متصلة بالـ IQ عن طريق ستة مداخل في أنوية Cortex A78 و Cortex X1، وتحمل وحدتي Branches “فروع”، هاتي الوحدتان مهمتهما التأكد أن الـ Branch Predictor قد تنبأ بفرع العمليات بشكل سليم، فإذا كان التنبؤ صحيحا فتقوم هاتين الوحدتين بإعلام الأجزاء السابقة من النواة بأن التنبؤ كان صحيحا، حتى يقوم الـ Decoder بسحب البرانش التالي من الـ Ins Cache؛ أما إذا كان التنبؤ غير صحيح، فتقوم وحدتي الـ Branches بإعلام الأجزاء السابقة لتفريغ محتوى الـ Predictor و الـ Decode وطلب فرع العمليات الصحيح.
وأخيرا وصلت التعليمات إلى مرحلة الـ Execution وحان البدء في تنفيذها عن طريق العمليات الحسابية مثل القسمة والضرب والجمع، والعمليات المنطقية، ولكن تنفيذها على ماذا؟ أي ماذا سيُضرب ويُجمع أو يُعرف كونه True أو False؟
إنها البيانات التي سنأتي بها من الذاكرة العشوائية. نعم، فكل ما كنا نقوم بجلبه وتفكيكه وتقسيمه إلى تعليمات صغيرة ونقله إلى طوابير التدفق حتى يصل إلى هنا، لم يكن إلا التعليمات التي بها التعديلات التي نريد تطبيقها على البيانات، وتلك البيانات تأتي مباشرة من الذاكرة العشوائية، ثم إلى ذواكر كاش الداتا من عدة مستويات، ومن ثم إلى وحدات الـ Execution Unit، في الوقت الذي يصل إليها التعليمات التي سيتم تنفيذها على تلك البيانات.
لكن هناك نوعين أساسيين من البيانات:
◆ بيانات الـ binary الصحيحة المكونة من (0-1).
◆ والبيانات المكونة من أعداد عشرية.
ويقوم قسم الـ Integer بمعالجة البيانات الصحيحة، والـ Floating Point تقوم بمعالجة الأعداد العشرية.
وأنوية Arm Cortex A78 لم تأتي بأي تحديثات جديدة في قسم الـ Floating Point عن أنوية كورتكس A77، أما الـ Integer فقد شهد تحديثا بسيطا في نوى Cortex A78 لكنه هام، وهو جعل أحد وحدات الـ ALU الأربعة المسؤلة عن العمليات الحسابية والمنطقية، قد أضافت دعم عمليات الـ MUL المسؤلة عن الضرب. مما يزيد من سرعة خروج عمليات الضرب بنسبة جيدة.
حسنا، لم يتبقى إلا الجزء الأخير من نواة Cortex A78 وهو المتعلق بجلب البيانات من كاشات البيانات أو من الذاكرة العشوائية، وهنا نرى أن ARM قد زادت عدد وحدات الـ AGU إلى ثلاث وحدات بدلا من اثنتين في الأنوية السابقة. ولفهم ما هي وحدات الـ AGU يجب أن نفهم أولا طريقة تعامل تعليمات ARM مع البيانات.
فمعالجات ARM لا تقوم بمعالجة البيانات مباشرة على الذاكرة العشوائية أو حتى على كاشات الـ DATA، بل تذهب بها أولا إلى المسجلات Registers كما تفعل مع التعليمات (Micro-Ops) ثم تذهب بالتعليمات والبيانات إلى وحدة الـ ALU للقيام بالعمليات المطلوبة.
وعملية نقل البيانات إلى المسجلات تحتاج إلى تنظيم فائق لمعرفة المسجلات الفارغة، وتنظيم نقل البيانات من إلى المسجلات، ثم إلى الكاشات أو الرام ثانية بعد مرورها بوحدات الـ ALU.
وهنا يأتي دور وحدتي التحميل (Load) و التخزين (Store)، فكلاهما وحدات تنظيم عنواين (Address Genration أو AGU)، وليستا وحدتي معالجة.
وتتمثل الزيادة هنا في Cortex A78 في إضافة وحدة LD إضافية ليكون المجموع وحدتان تخزين، مع البقاء على وحدة الـ ST منفردة لكن مع مضاعفة واجهة الدخول إلى الكاش من 16 بايت إلى 32 بايت في الدورة الواحدة.
يتضح مما سبق أن أنوية Cortex A78 لا تسعى إطلاقا إلى زيادة الأداء، بل كل التغيرات التي تمت عليها إنما هي لتوفير الطاقة في الأصل مع تصغير حجم النواة قدر المستطاع وهذا ما سنراه في قسم نتائج الأداء في نهاية المقال.

أنوية ARM Cortex X1 الأداء قبل كل شيء..
تضع ARM أنوية Cortex X1 تحت قسم الأنوية المعدلة خلافا لأنوية Cortex A76 الموضوعة تحت قسم الأنوية الخام، هذا رغم أن الشركة هي من قامت بتصميمها، ففي السابق كانت ARM تصمم أنويتها الخام وتقوم بعض الشركات بإستخدامها كما هي والبعض الآخر بالتعديل عليها.
لكن لما فشلت بعض الشركات مثل سامسونج في إنجاح تصاميمها المعدلة، وحقيقة أن أنوية Kryo من كوالكوم ما هي إلا إعادة تسمية لإنوية ARM الخام! يبدو أن الشركة قد قررت تقديم بديلها الخاص حتى لا تتأخر عن باقي المنافسين.
ورغم فارق الأداء الكبير بين أنوية Cortex X1 و Cortex A78، لكنهما يشتركان في أغلب أجزاء التصميم لكن مع زيادة الوحدات و خطوط الإمداد ومساحة الكاشات في جميع اجزاء النواة في Cortex X1. لهذا لن يكون الشرح التالي شرحا مفصلا كما السابق، إنما سيكون مناقشة التغيرات التي يقدمها تصميم Cortex X1 على تصميم Cortex A78.
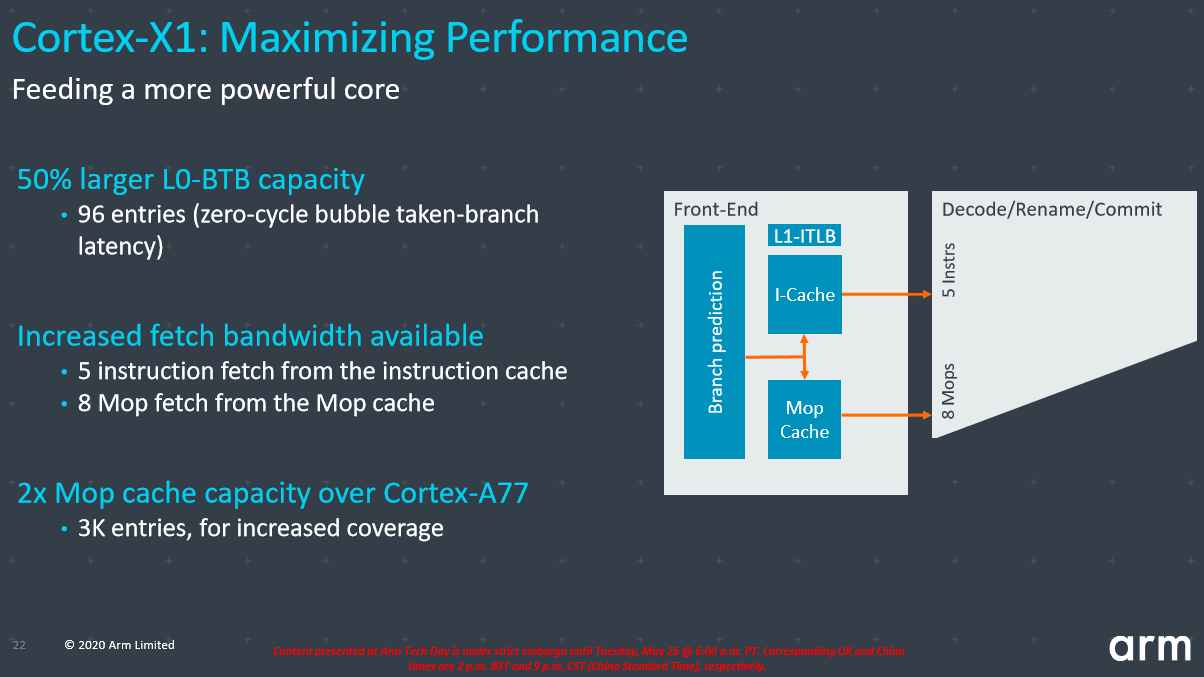
أولاً: مرحلتي الـ fetch و الـ decode:
لم تقدم أنوية Cortex X1 أي اختلاف فيما يتعلق بوحدة الـ branch prediction، فبالفعل هذه الوحدة قد تم تطويرها بشكل كبير في Cortex A78. أما الكاشات فهي التي شهدت تحديثا جيدا، فالـ Instruction Cache لا يأتي بخيارين 32 أو 64 بت كما في Cortex A78، بل يوجد الخيار الأكبر 64 بت فقط.
والتغيير الأكبر يأتي مع Mop كاش، فقد أصبح الآن قادر على تخزين 3000 عملية مصغرة بعد خروجها من الـ Decoder بدلا من 1500 عملية فقط في A78.
وقد أصبحت واجهة مرحلة الـ Fetch اوسع، بحيث يستطيع الـ Decoder سحب 5 عمليات (Inst) بدلا من أربع عمليات في Cortex A78، هذا بالإضافة إلى أن وحدة الـ Rename تستطيع الآن الحصول على 8 عمليات مصغرة من وحدة M-Ops بدلا من 5 فقط في Cortex A78.
وبفضل الواجهة الأعرض بين مرحلتي الـ Fetch و الـ Decode، يمكن الآن أن تحمل مرحلة الـ Decode واجهة أعرض إلى مرحلة الـ Execute. وهذا هو الحال بالفعل مع أنوية Cortex X1 فالواجهة إلى مرحلة الـ Execute تستطيع الآن نقل 8 عمليات ماكرو بدلا من 6 عمليات في Cortex A78، ناهيك عن 5 عمليات فقط في أنوية A77.
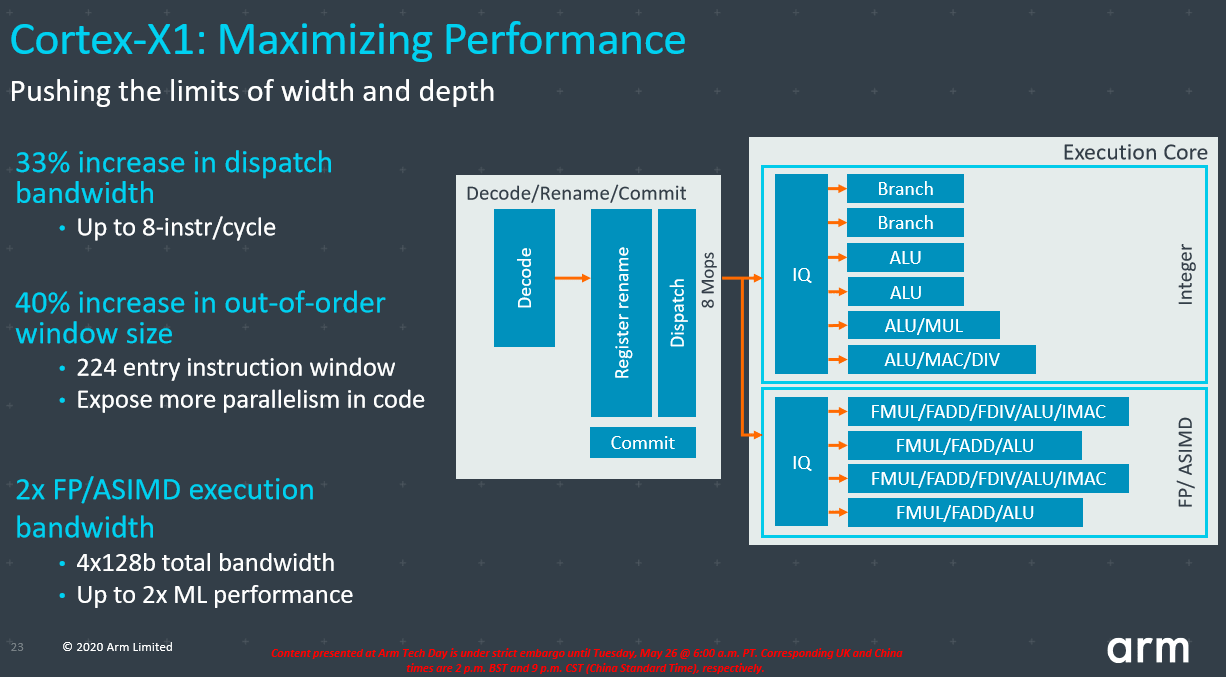
ثانيا: مرحلتي الـ Executeو الـ Write Back:
استمرارا للتغييرات الكبيرة التي تقدمها أنوية Cortex X1، تشهد مرحلة الـ Execute العديد من التغيرات الهامة. بداية من واجهة الـ IQ التي أصبحت الآن بحجم 224 مدخل بدلا من 160 مدخل فقط في أنوية A77، مما يتيح زيادة كبيرة للعمليات الداخلة لوحدات الـ ALU.
بعد أن يتم تجهيز العمليات في طوابير الإنتظار، يتم نقلها إلى الـ Integer Unit أو الـ Floating Unit. وتحمل أنوية Cortex X1 نفس قسم الـ Integer الموجود في Cortex A78 و الذي حمل تحسينات جيدة عن سابقه.
أما قسم الـ Floating unit هو الذي قد حصل على تعديلات كبيرة. فقد تم مضاعفة عدد الوحدات في هذا القسم. بحيث تم استنساخ الوحدات الموجودة في Cortex A78 لكن مع مضاعفة كل وحدة لنحصل على زيادة كبيرة في أداء عمليات الـ Float.
وبالوصول إلى مرحلة الـ Write Back نجد عدة تغيرات إيجابية ايضا خاصة على مستوى الكاش. فتقدم أنوية Cortex X1 كاش بيانات من المستوى الأول ( L1D) بحجم 64 كيلوبايات فقط ولا تعطي للشركات خيار الـ 32 كيلوبايت.
أما الكاش من المستوى الثاني فيصل إلى 1 ميجابايت بدلا من 512 كيلوبايت في Cortex A78، هذا مع زيادة سرعة الكاش نفسه ليصل معدل التأخير إلى 10 دورات بدلا من 11 دورة في Cortex A78.
وأما كاش المستوى الثالث فيصل الآن حتى 8 ميجابايت بدلا من 4 ميجابايت في Cortex A78.
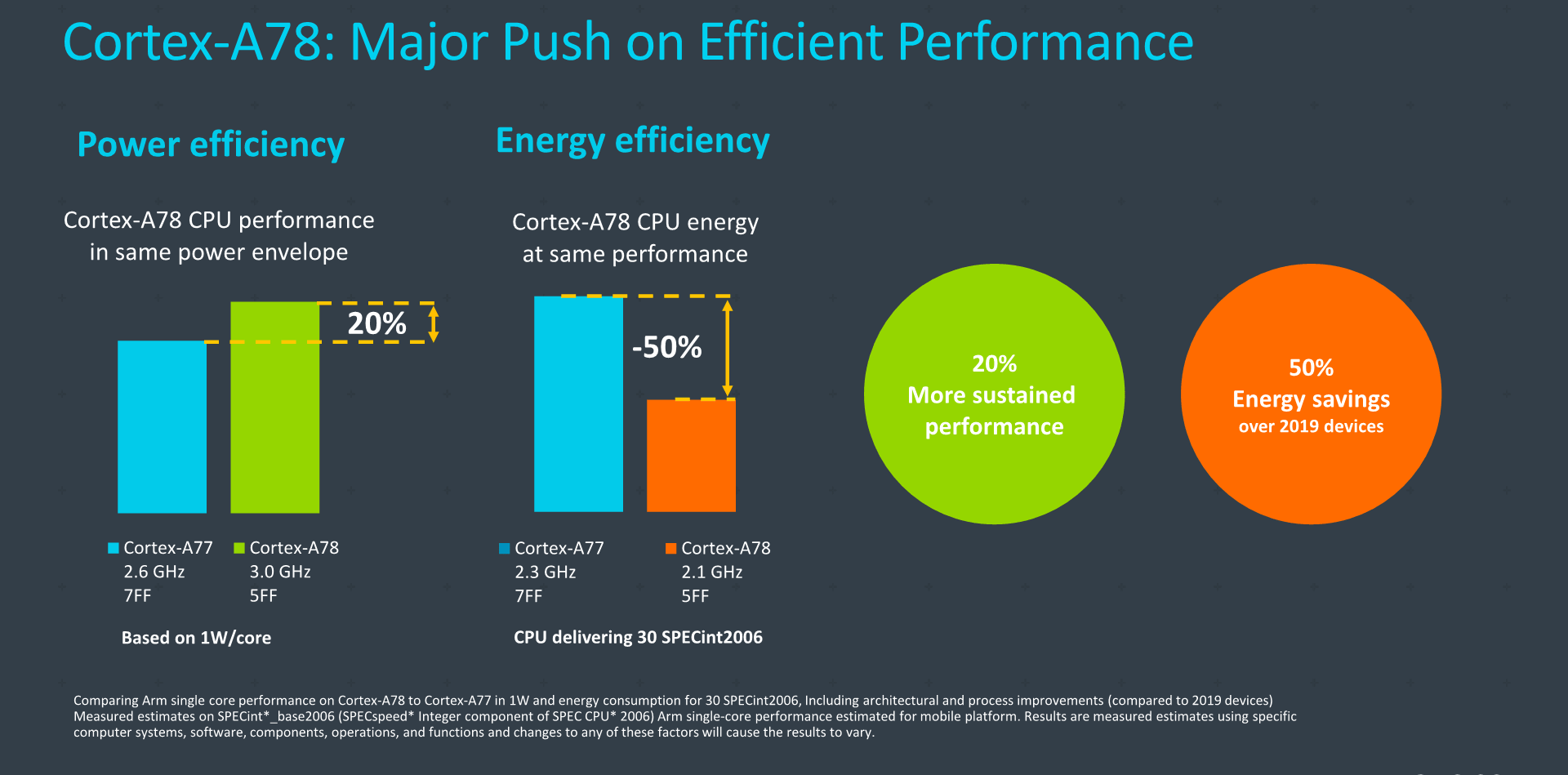
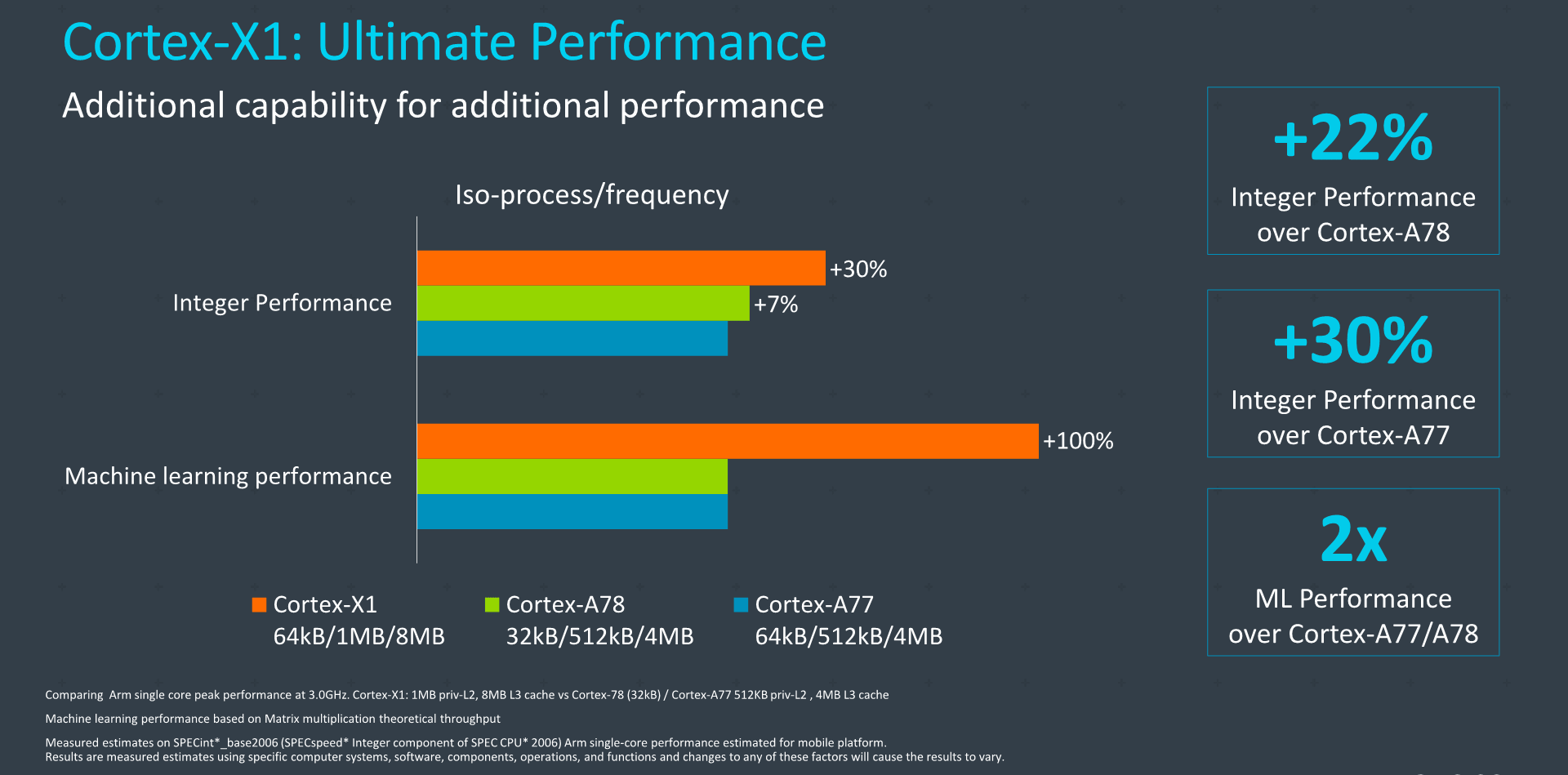
الأداء: Cortex A78 تقلل استهلاك الطاقة إلى النصف وCortex X1 تعطى أداء أفضل بـ 30 بالمائة
“أكثر نواة موفرة للطاقة في أنوية سلسلة A المخصصة للأداء” هكذا عبرت ARM عن أنوية Cortex A78، ويمكننا بالفعل القول بأن هذه العبارة صحيحة للغاية. فكما وضحنا في التصميم، فإن أغلب التعديلات التي قدمتها ARM كانت تهدف في الأساس لتوفير الطاقة وخفض المساحة الكلية.
وتبعا لما قدمته ARM فإن أنوية Cortex A78 تستطيع تقديم أداء أفضل بنسبة 20 بالمائة مع الحفاظ على نفس استهلاك الطاقة، هذا إذا قارنت أنوية ARM Cortex A78 المصنعة بتقنية 5 نانومتر وبتردد 3 جيجاهرتز مع أنوية A77 المصنعة بتقنية 7 نانومتر الأقدم وبتردد 2.7 جيجاهرتز.
وزيادة 20 بالمئة في الأداء ليست سيئة على الإطلاق، لكن هذا على افتراض أن شركة المعالجات ستستخدم تردد 3 جيجاهرتز لأنوية Cortex A78، لكن على الأرجح أنها ستستخدم بتردد أقل من هذا، أي سيكون الفارق في توفير الطاقة غالبا وليس الأداء.
ورغم أن الأرقام بالأعلي ليست شيقة، لكن ARM قدمت رقما مميزا للغاية، حيث تستطيع أنوية Cortex A78 استهلاك طاقة أقل بنسبة 50 بالمئة إذا ما تم استخدامها بتردد 2.1 جيجاهرتز، مع تقديم نفس أداء أنوية A77 بتردد 2.3 جيجاهرتز!
كما بينا في شرح تصميم أنوية ARM Cortex X1 فإن الشركة لم تكن تسعى إطلاقا للحفاظ على استهلاك الطاقة وحجم النواة كما في تصاميمها المعتادة. بل كان الهدف الأول من البرنامج الجديد هو الحصول على أفضل أداء ممكن. وقد وصلت النواة الجديدة إلى أرقام جيدة للغاية رغم بنائها على نفس الأسس التصميمية لأنوية Cortex A78.
فتستطيع أنوية Cortex X1 أن تقدم أداءا أفضل بنسبة 30 بالمائة إذا ما قورنت بأنوية A77، أي حوالي زيادة 22 بالمئة في الأداء إذا ما قورنت بأنوية Cortex A78. ولكن هذه النتائج إذا تم استخدام أقصى حجم للكاشات وهو 64 كيلوبايت للكاش من المستوى الأول, و 1 ميجابايت للكاش من المستوى الثاني, و 8 ميجابايت للكاش من المستوى الثالث.
فلا تتوقع الحصول على تلك النتائج مع Snapdragon 888 مثلا الذي يستخدم كاشات أقل كما بينا في مراجعتنا التفصيلية له.
لكن يوضع الأمل في الحصول على نتائج مشابهة من شريحة Exynos 2100 الذي يتوقع أن يأتي بكاشات بحجم أكبر وغالبا أنوية أعلى في التردد.
ورغم أن ARM لم تفصح عن حجم النواة الجديدة أو استهلاكها للطاقة، لكن يمكننا التوقع أن تتخطى الزيادة الـ 40 بالمئة في الحجم واستهلاك الطاقة مقارنة بأنوية Cortex A78.
خيارات الشركات: كيف يمكن تنظيم أنوية Cortex X1 و A78 داخل المعالج المركزي؟
إضافة ARM لخيار أنوية Cortex X يزيد من خيارات الشركات في إنشاء تصاميم متنوعة للمعالج المركزي، هذه التصاميم على كثرتها أكثر من أي وقت مضى.. إلا أني أعتقد أن أعلب الشركات ستقوم باستخدامها بالشكل الخاطيء.
فكثير من الشركات التي ستقدم شرائح للفئات المتوسطة لن تذهب على الأرجح إلى استخدام أنوية Cortex X1 وستستعيض عنها برفع ترددات أنوية Cortex A78 بشكل كبير، وغالبا هذه المعالجات لن تكون مبنية على أحدث تقنية تصنيع لخفض التكلفة. مما سيجعل المعالج غير قادر على الحفاظ على هذه الترددات العالية لفترة طويلة. وفي هذه الحالة، لن تحصل المعالجات المتوسطة على فارق كبير في الأداء لكن على الأرجح أغلب التحسينات ستكون فيما يتعلق بتوفير الطاقة.
أما المعالجات الرائدة فيفترض أن تكون أكثر من يستفيد بالتصميمات الجديدة، فبدلا من الإعتماد على أنوية سلسلة A المتأخرة في أداء النواة المنفردة، يمكن تقسيم الـ Cluster المخصصة للأداء بين أنوية Cortex X و أنوية Cortex A. لكن هذا ما لم نراه بشكل جيد حتى الآن، فمعالج Snapdragon 888 لم يأت إلا بنواة واحدة من نوع Cortex X1، ورغم أن هذا قد يكون جيدا إذا استخدمتها كوالكوم بتردد مرتفع، لكن هذا لم يحدث وقررت كوالكوم استخدامها بتردد 2.8 جيجاهرتز فقط. فهذا يزيد من استهلاك الطاقة بشكل كبير دون الحصول على فارق أداء كبير يعوضه.
– لكن ما أنتظره شخصيا، هو تصميم (2+2)+(4) بحيث يحمل المعالج نواتين Cortex X1 و نواتين Cortex A78 وأربع أنوية Cortex A55.
ونتمنى أن نرى هذا من سامسونج في Exynos 2100 القادم، وربما ميدياتك إذا قررت الدخول بقوة لعالم المعالجات الرائدة. في تصميم مثل هذا قد نرى لأول مرة منذ فترة طويلة شرائح مخصصة لهواتف الأندرويد قادرة على منافسة رقاقات ابل، وربما نرى بعض التصميمات تتغلب على Apple A14، حتى وإن لم تتغلب عليها في نتائج أداء النواة الواحدة.
قد لا يكون نتائج البرنامج الجديد من ARM هي المرجوة بالضبط في الوقت الحالي، لكنها خطوة جيدة في الإتجاه الصحيح، من المرجح أن نتائج البرنامج الجديد ستظهر بقوة في العام التالي، بحيث ربما نرى أخيرا خليفة لأنوية A55 مبنية على المباديء التصميمية لأنوية Cortex A78. وربما نرى أنوية Cortex X2 بتصميم مغاير تماما عن أنوية سلسلة A.

